浅拷贝,好样的!
2022年7月29日 · 112 字 · 1 分钟 · 深拷贝 浅拷贝 Deep Clone Occasion 数组 表格 排序
原文地址:https://jaufey.notion.site/16304b150a7142fea50ee371afdc1234
基本需求
前些天,写了一个表格。这个表格,有下面几个功能:
-
行排序
点击列头对所有数据按照此列应用行排序。
- 点第 1 下是升序
- 点第 2 下是降序
- 点第 3 下取消排序
- 支持多列排序
-
列排序
左右拖动列头,可对表头进行左右排序。当然,表体要随表头更新。此功能不需要取消排序。
数据结构
数据结构是这样的:
headers:
[name, age, desc]
bodys:
[
[ name3, age3, desc3 ],
[ name2, age2, desc2 ],
[ name1, age1, desc1 ],
]
以上两个功能我实现得很好,但行列排序没有好讲的,而且不是本文重点。之后可针对列排序写一篇交互上的文章。本文的重点在 “取消排序”。
取消排序
如何将已排好的行数据恢复初始状态呢?
当然是存储一份原始数据了,在点击表头第三下的时候就拿出原始数据渲染出来。
const originalRows = await getRows(); // 保存的初始数据,恢复乱序时使用。
const sortedRows = [...originalRows]; // 行列排序的操作应用在此变量中,并渲染此变量在页面中。
问题出现
想一想,我们有两个功能:行排序和列排序。一个可能会发生的冲突在我脑中浮现。
在我的想象中,制造冲突的步骤如下:
-
拖动第1列表头到最末尾,对数据应用列排序:
headers: [age, desc, name] -
点击任意表头,按照此列对数据应用行排序
-
点至第 3 下,取消基于此头的行排序
那么,按照上面讲的,我们需要拿 originalRows 出来渲染。
这个时候,已应用的列排序不就失效了吗?
又会变成初始时的这个样子?
headers: [name, age, desc]
虚惊一场
不,已应用的列排序不会失效。
为什么呢?因为缓存原始数据时,没有使用深拷贝。
在我的印象里,虽然深拷贝是昂贵的,但在很多场景里,它的不得已出现总是为了解决问题的。比起 “深拷贝耗能过多”,“浅拷贝隐式修改同一变量而造成混乱” 的问题,似乎更常见也更严重。
但在本文的场景中,浅拷贝反而帮助了我。
为什么
下面一张图来说明:已应用的列排序为什么不会失效。
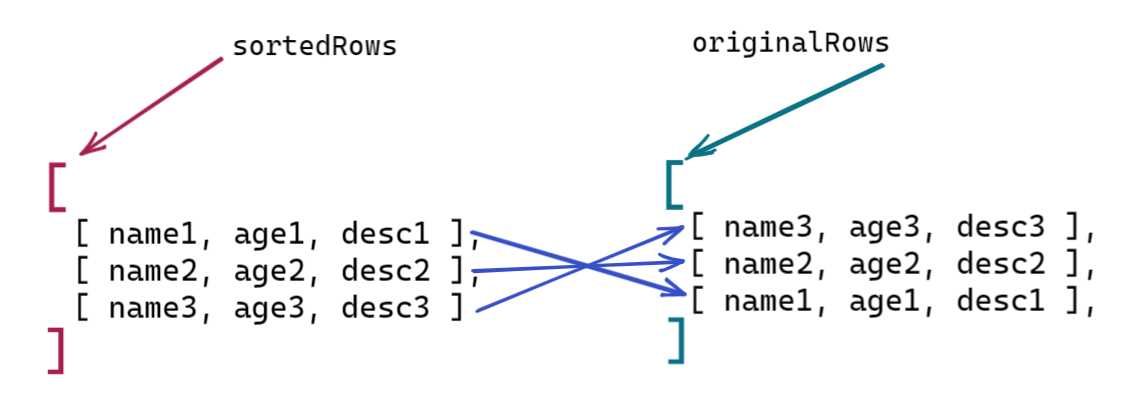
文字描述:
- 因为
sortedRows = […originalRows],使得左右两个数组:- 外层是不一样的引用对象;
- 内层的各个子元素是相同的引用对象。
- 应用列排序时,我们在
sortedRows中置换了各行中列的顺序,因为没有深拷贝,所以同步修改了originalRows中各行中列的顺序。 - 而应用行排序时,我们只改变了各行引用在
sortedRows中的顺序。
总结
总的来说,我的操作是误打误撞的,但我们可以似乎可以多思考一下:
-
浅拷贝和深拷贝的分法可能是不合适的,粒度太粗了。现在我们只把所有深度都拷贝了的拷贝叫做深拷贝。除此之外的都不叫深拷贝,也就是浅拷贝了。
-
或许,我们应该依据拷贝的深度分出这么几个粒度:
【零拷贝,浅拷贝1,浅拷贝2,浅拷贝3,深拷贝4,深拷贝5,深拷贝6,全拷贝】 -
从本文来看,我看到了非深拷贝的巨大潜力。我发誓我他妈爱上了浅拷贝。
-
在特定场景下拷贝到特定层级,可以结合浅拷贝的优势和深拷贝的优势。